Link Status determines the result of the link crawling and interpretation of tags in HEAD and Robots.txt (Follow, NoFollow, Mention, Redirect, Unverified).
| Metric | Description |
|---|---|
| Follow | A Follow link is indexed and influences the ranking of the target page. |
| NoFollow | The impact on NoFollow links on search engine rankings and penalties is discussed controversially. Google published that such links would be completely ignored. We have the opinion that NoFollow links can under certain circumstances still be harmful to search engine rankings and result in manual penalties because Google generally tries to identify spamming intents. |
| Mention | The URL was mentioned, but not linked. This type of link can increasingly be found in forums and the like if the entered URLs are not automatically converted into links. |
| Redirect | The URL is identified as original resource link by another page. See below for possible redirect codes. |
| Canonical | The URL has been identified as original source by a site with duplicate content. |
| [LinkNotFound] | No link has been found on the particular page. It is possible that it has been deleted in the meantime or slipped down to the next page on a list or in a blog, etc. |
| n/a | It was impossible to search for a link in this URL, because, for instance, it comes from a file, such as a PDF or an image. |
| Error | The particular page/ URL could not be checked by our crawlers, or it was temporarily unavailable. |
| Unverifed | The link could not be verified |
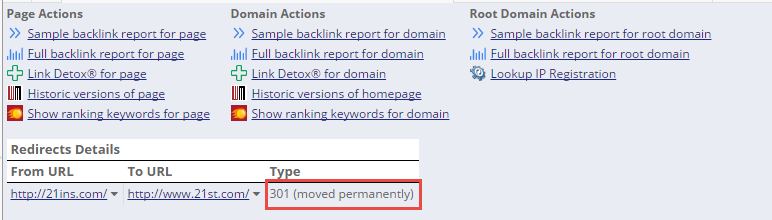
Possible Redirect codes
- 300 multiple choices
- 301 (moved permanently)
- 302 (found)
- 303 see other
- 307 (temporary redirect)
- Refresh Meta tag
- HTTP refresh header
- Rel Canonical (Statement by Google)
Redirect Trace
In case a link is identified as a redirect, you can query a detailed Link Redirect Trace by clicking on the “+” next to the source URL.
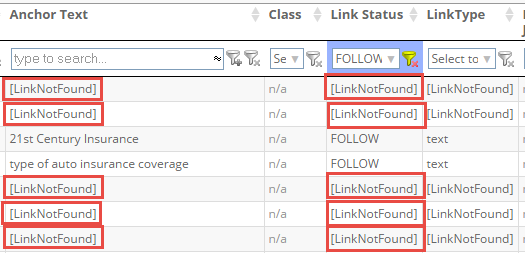
LinkNotFound
In case that a link was removed, it is marked accordingly as [LinkNotFound] in the link detail table.
It is also possible to remove these no longer existing links (as well as site-wide links) before the report is created.
Unverified Link Status
A link marked as “unverified” when we tried to crawl the link but could not verify that the link was present.
This can be because the website blocks our crawlers. Other reasons can be, for example, that the site was temporarily down.
It is often helpful where a link is shown as ‘Unverified’ to have the option to see the specific (technical) reason why Link Detox was not able to crawl the link.
You can see additional helpful details about a link reviewing the HTTP-Code and the Network Errors.
Why are unverified links important to you?
Link Detox crawls all the links we get from our sources and those you upload. However, there are some special sites, such as reddit.com, that usually returns a 429 Error Code. This is probably to make it hard for content scrapers.
If LRT cannot verify a link because the crawlers are blocked it does not necessarily mean that the link is dropped, so it is marked as unverified.
If LRT cannot verify a link exists, you should not assume that it has been dropped. It could very well come back a minute after the crawler visited it first.